Fullstack Engineering
Fullstack engineering is a bit of a broad topic. It's a lot like a general practitioner in the medical field. You probably wouldn't want that MD doing brain surgery but they are a great place to start diagnosing your problem.
My fullstack engineer skills are the prescription for your application pains.
Below you will find some of the fullstack projects I have recently worked on.
Reducing data cycle time
Yale New Haven Hospital is the 3rd largest hospital network in the United States. Many of the residents perform data analysis on a routine basis. Yale was seeking a solution to
- improve access to data
- reduce the time to retrieve data
- quickly verify data access permissions
- maintain data security in a permissioned environment
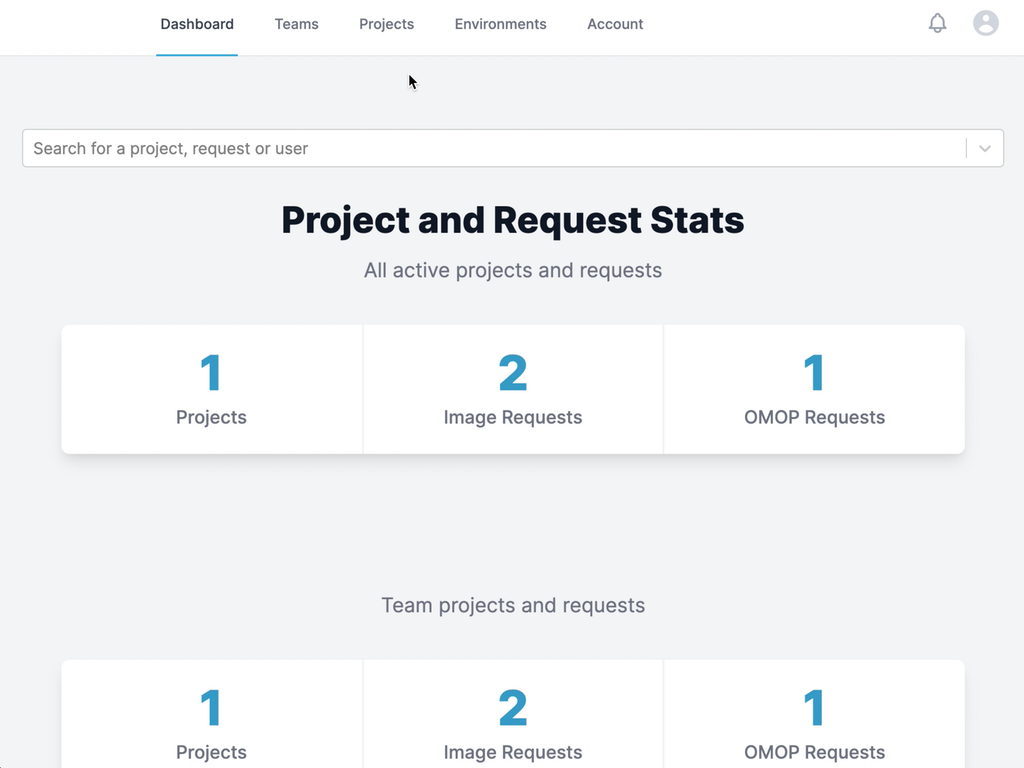
The application front-end is a React app. User authentication was done with the existing Microsoft Active Directory. Access and roles within the app were administered via AD Group membership.
Business logic and data persistence were handled by a NodeJS API server using ExpressJS. Registered users could create a new data request, indicating the patient identifiers or medical criteria as determined by their project needs.
Requests were saved in a "pending" state, awaiting review for access approval and to confirm the data request was in accordance with the approved study details. Once verified, an admin with proper permissions approved the data request.
Once approved, the API submitted request messages via RabbitMQ to various job runners based on the data being requested. Job runners were python-based applications running as docker containers. Each was purpose built to retrieve data from a specific data store, ie. images from a patient imaging archive server, or patient medical records from an Electronic Health Record (EHR) database.
Each runner would save the data it collected in an NFS share specified by the API. Permissions on the NFS share were restricted to the team making the request, and collected data was marked as read-only to ensure the integrity of the data did not change.
After data collection is completed, the requestor is notified and the database updated. The requestor can then launch a dynamic Jupyter Notebook to analyze the data. The saved data is mounted in a read-only volume in a docker container, along with a read-write volume for saving and sharing data analysis results with the team.
The entire environment ran on a Kubernetes cluster housed in the Yale New Haven datacenters. Applications were deployed as Kubernetes services. Jupyter Notebooks were launched using an additional runner to dynamically provision resources based on the desired number of CPU, Memory, and GPU parameters as well as mounting the NFS shares for the project. Jupyter Notebooks were launched within a namespace for the Requestor's team. Namespaces has hard memory, CPU, and GPU constraints to ensure no team could more resources than allotted.
Proven skills backed by a network of trust
This is a personal project of mine because interviewing for jobs sucks. We spend so much time evaluating a candidates technical skills, we overlook whether or not they are a good cultural fit. Or, we turn an interview process into a multi-week, 8 interview process that consumes so much time we simply cannot find the right candidate.
Leetproof fixes that by proving a candidate's technical skills using a network of trust.
This is a work in progress. Screenshots and details will be posted here as available. Meahwhile, check out Trustified.io for a project overview. (Trustified was the original project name before I decided I liked Leetproof better. Once I launch the site, this URL will be updated.)